In this post, we’ll explore strategies to control randomness in LLMs, discuss trade-offs, and provide some code examples in Python using the OpenAI API.
Large Language Models (LLMs) like GPT-4, Claude, or LLaMA are probabilistic by design. They generate text by sampling the most likely next token from a distribution, which introduces randomness into their outputs. This variability can be both a feature (creativity, diversity) and a challenge (inconsistent answers, reproducibility issues).
Table of contents
Why Control Randomness?
Randomness influences:
- Consistency – Lower randomness helps you get repeatable results for testing or production.
- Creativity – Higher randomness allows more diverse ideas, but may drift from the intended tone.
- Evaluation – When comparing prompts or models, reducing randomness ensures a fair test.
If you’re building chatbots, summarizers, or compliance tools, too much randomness can break reliability. On the other hand, if you’re generating marketing copy or brainstorming ideas, you may want more variation.
Key Parameters for Controlling Randomness
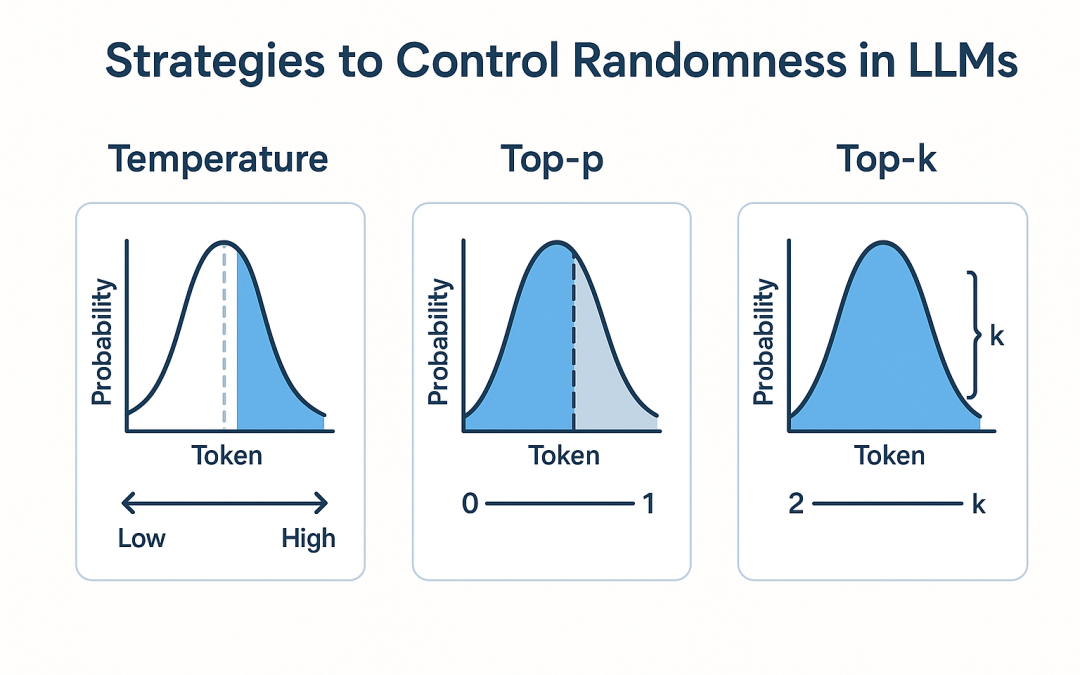
1. Temperature
Temperature controls the “sharpness” of the probability distribution over possible tokens.
- Low values (0.0 – 0.3) → Deterministic, predictable outputs.
- Medium values (0.4 – 0.7) → Balanced creativity and accuracy.
- High values (0.8 – 1.5) → Diverse, creative, sometimes nonsensical outputs.
Example:
from openai import OpenAI
client = OpenAI()
prompt = "Write a short haiku about the ocean."
# Low temperature
response_low = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.2
)
# High temperature
response_high = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=1.0
)
print("Low temperature:", response_low.choices[0].message.content)
print("High temperature:", response_high.choices[0].message.content)
You’ll notice the low-temperature output is more literal and predictable, while the high-temperature one may use unusual imagery or structure.
2. Top-p (Nucleus Sampling)
Top-p limits the set of tokens considered for each step to those whose combined probability mass is ≤ p.
- Low values (0.1 – 0.3) → Conservative, focused outputs.
- High values (~1.0) → Almost no filtering, more variation.
Example:
response_top_p = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "List some unusual ice cream flavors."}],
temperature=0.7,
top_p=0.5
)
print(response_top_p.choices[0].message.content)
If top_p is 0.5, only the most probable half of the distribution is considered at each token step, cutting out rare words.
3. Top-k Sampling
Some APIs and libraries also provide top-k, which considers only the k most likely tokens.
- Small k (e.g., 10) → More deterministic.
- Large k → More variety.
Example (Transformers library):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_ids = tokenizer("Tell me a riddle about space:", return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
do_sample=True,
temperature=0.7,
top_k=40,
max_length=50
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
4. Setting a Fixed Random Seed
For complete reproducibility (in local inference scenarios), you can set a random seed. This works well with open-source models where you control the generation process.
import torch
import random
import numpy as np
seed = 42
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
Note: This doesn’t apply to most cloud-hosted APIs like OpenAI, where generation randomness is server-side and non-deterministic unless you set temperature to 0.
5. Greedy Decoding
Setting temperature=0 (and optionally disabling top-p/top-k) makes the model always pick the highest probability token.
response_greedy = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Explain quantum computing in one sentence."}],
temperature=0
)
print(response_greedy.choices[0].message.content)
Greedy decoding ensures full determinism, but can make text repetitive or less creative.
Combining Strategies
You can combine parameters for fine-grained control. For example:
- High determinism:
temperature=0.0,top_p=1.0 - Balanced creativity:
temperature=0.7,top_p=0.9 - Exploratory brainstorming:
temperature=1.0,top_p=1.0,top_k=100
Best Practices
- Know Your Use Case
- For legal, compliance, or factual answers → Low randomness.
- For storytelling, brainstorming → Higher randomness.
- Test Multiple Settings
Don’t assume one setting fits all tasks. Try a grid of(temperature, top_p)pairs. - Evaluate Outputs
Compare generations not only on diversity but also on factual accuracy and tone. - Document Your Parameters
In production, log temperature, top-p, and other sampling settings to ensure reproducibility.
Conclusion
Randomness in LLMs is a powerful dial — too little, and your model feels rigid; too much, and it becomes unpredictable. By tuning temperature, top-p, top-k, using seeds, and understanding decoding strategies, you can align the model’s output with your application’s needs.
Whether you want your AI to deliver consistent customer support answers or generate wild, imaginative stories, mastering these randomness controls gives you the creative steering wheel.