In this article, we’ll explore How to Use the tiktoken Tokenizer, why it matters, and practical ways you can apply it in your projects to better control prompts, estimate API costs, and optimize large text inputs.
Table of contents
When working with large language models (LLMs) like GPT-4, GPT-4o, or GPT-3.5, understanding tokens is crucial. Tokens are the basic units of text that models process—think of them as word pieces rather than whole words. For example, the word tokenization might split into multiple tokens, while short words like cat are typically a single token.
The tiktoken library, developed by OpenAI, is a fast and efficient tokenizer that allows developers to understand, count, and manage tokens when interacting with LLMs. Whether you’re optimizing prompts, estimating costs, or debugging issues, tiktoken is the tool that helps you stay in control.
In this post, we’ll cover what tiktoken is, why it matters, and how to use it step by step.
Why Tokenization Matters
Before diving into code, let’s quickly revisit why tokenization is important:
- Model limits: Each model has a maximum context window (e.g., GPT-4o supports up to 128k tokens). Exceeding this limit will cause your request to fail.
- Costs: Most APIs charge per 1,000 tokens. Knowing token counts helps estimate costs before you send requests.
- Prompt engineering: Understanding how text is broken down helps you write more efficient prompts.
- Debugging: When your input gets unexpectedly truncated or rejected, tokenization often explains why.
Installing tiktoken
tiktoken can be installed directly from PyPI:
pip install tiktokenIt’s lightweight and has no complex dependencies, so installation is usually smooth.
Basic Usage
The first step is to import the library and load an encoding. Encodings are model-specific, meaning that different models tokenize text differently. For example, GPT-3.5 and GPT-4 use the cl100k_base encoding.
import tiktoken
# Load encoding for GPT-4 / GPT-3.5
encoding = tiktoken.get_encoding("cl100k_base")
# Encode text
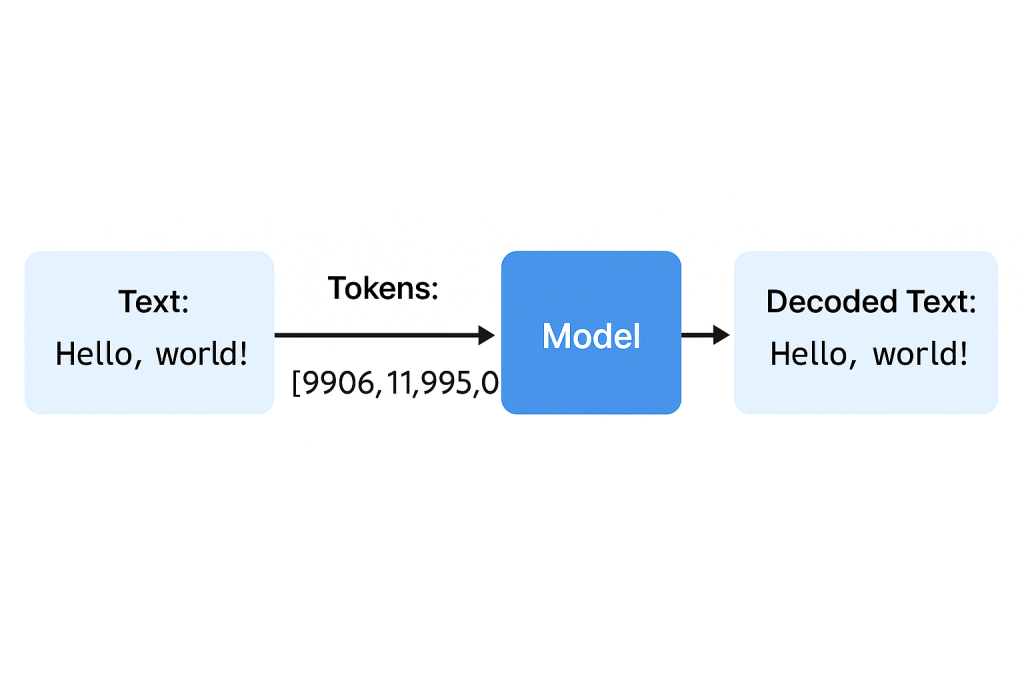
text = "Hello, world! Tokenization with tiktoken is fast."
tokens = encoding.encode(text)
print(tokens)
The output will be a list of integers (token IDs). Each ID corresponds to a token in the model’s vocabulary.
For example:
[9906, 11, 995, 0, 36308, 284, 11299, 374, 220, 220]Decoding Tokens Back to Text
If you want to check what those IDs represent, you can decode them back into strings:
decoded_text = encoding.decode(tokens)
print(decoded_text)
Output:
Hello, world! Tokenization with tiktoken is fast.This round-trip process ensures you know exactly how text is represented internally.
Counting Tokens
One of the most common use cases is simply counting how many tokens a string contains. This is especially useful when preparing prompts for the OpenAI API.
def count_tokens(text: str, encoding_name: str = "cl100k_base") -> int:
encoding = tiktoken.get_encoding(encoding_name)
return len(encoding.encode(text))
sample = "Large language models are powerful, but token limits matter."
print(count_tokens(sample)) # Output: e.g., 11
This gives you precise control over text length and cost estimation.
Using Model-Specific Encodings
Instead of manually specifying cl100k_base, you can directly load the encoding for a specific model. tiktoken has utilities to handle this:
encoding = tiktoken.encoding_for_model("gpt-4o")
text = "This text will be tokenized using GPT-4o's encoding."
tokens = encoding.encode(text)
print(tokens)
This is safer than hardcoding, since OpenAI occasionally updates encoding schemes for newer models.
Working with Long Texts
When dealing with long documents, you may want to chunk text into smaller pieces to fit within model limits.
def chunk_text(text: str, max_tokens: int = 500):
encoding = tiktoken.encoding_for_model("gpt-4o")
tokens = encoding.encode(text)
# Split into chunks
for i in range(0, len(tokens), max_tokens):
yield encoding.decode(tokens[i:i+max_tokens])
# Example usage
for chunk in chunk_text("Your very long document goes here...", max_tokens=1000):
print(chunk)
This ensures that each API call stays within the model’s context window.
Estimating API Costs with tiktoken
Let’s say you’re using GPT-4o, and the pricing is $0.002 per 1,000 input tokens. You can estimate costs like this:
def estimate_cost(text: str, model: str = "gpt-4o", rate_per_1k: float = 0.002):
encoding = tiktoken.encoding_for_model(model)
num_tokens = len(encoding.encode(text))
cost = (num_tokens / 1000) * rate_per_1k
return num_tokens, cost
sample = "OpenAI models are great for summarization, Q&A, and much more."
tokens, cost = estimate_cost(sample)
print(f"Tokens: {tokens}, Estimated cost: ${cost:.6f}")
Output example:
Tokens: 14, Estimated cost: $0.000028Advanced Features
- Byte pair encoding (BPE):
tiktokenrelies on BPE, a subword tokenization method. You can explore how words break down into pieces. - Custom encodings: It’s possible to load custom encoding files if you’re experimenting with fine-tuned models.
- Debugging hidden tokens:
tiktokenhelps identify newline characters, spaces, and special tokens (likeENDmarkers).
Best Practices
- Always check tokens before API calls – prevent errors by validating input size.
- Chunk smartly – break large texts at logical boundaries (sentences, paragraphs).
- Cache encodings – loading encodings repeatedly can be slow; reuse them across calls.
- Mind the prompt + response – remember that output tokens also count toward limits and costs.
- Stay model-specific – different models tokenize differently, so always pick the right encoding.
Conclusion
The tiktoken library is an essential tool for anyone working with OpenAI’s models. By understanding how text is tokenized, you gain the ability to optimize prompts, estimate costs, and avoid hitting model limits. From simple token counting to advanced text chunking strategies, tiktoken helps you take full control of how your text is processed.
If you’re building applications with GPT models, learning to use tiktoken is not optional—it’s a must. With just a few lines of Python, you can gain deep insight into how your prompts are represented under the hood.