by CPI Staff | Feb 1, 2026 | Blog, LangChain
In this blog post Protect Against LangGrinch CVE-2025-68664 in LangChain Apps we will walk through what the vulnerability is, why it matters, and the practical steps you can take to reduce risk in real-world LangChain deployments. LangChain is popular because it helps...
by CPI Staff | Sep 25, 2025 | Blog, LangChain, LLM
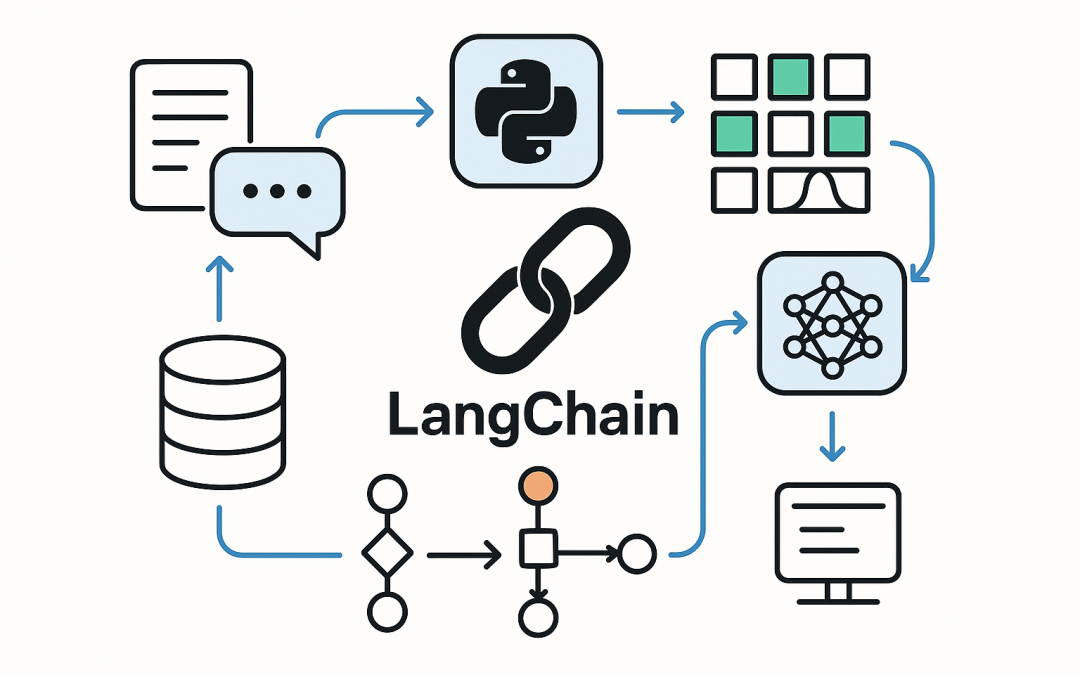
In this blog post Supercharge LangChain apps with an LLM cache for speed and cost we will show how to make LangChain applications faster, cheaper, and more reliable by caching LLM outputs. Supercharge LangChain apps with an LLM cache for speed and cost is about one...
by CPI Staff | Sep 25, 2025 | AI, Blog, LangChain
In this blog post Running Prompts with LangChain A Practical Guide for Teams and Leaders we will walk through how to design, run, and ship reliable prompts using LangChain’s modern building blocks. Why prompts and why LangChain Large language models respond to...
by CPI Staff | Sep 25, 2025 | AI, Blog, LangChain
In this blog post LangChain architecture explained for agents RAG and production apps we will unpack how LangChain works, when to use it, and how to build reliable AI features without reinventing the wheel. At a high level, LangChain is a toolkit for composing large...
by CPI Staff | Sep 25, 2025 | AI, Blog, LangChain
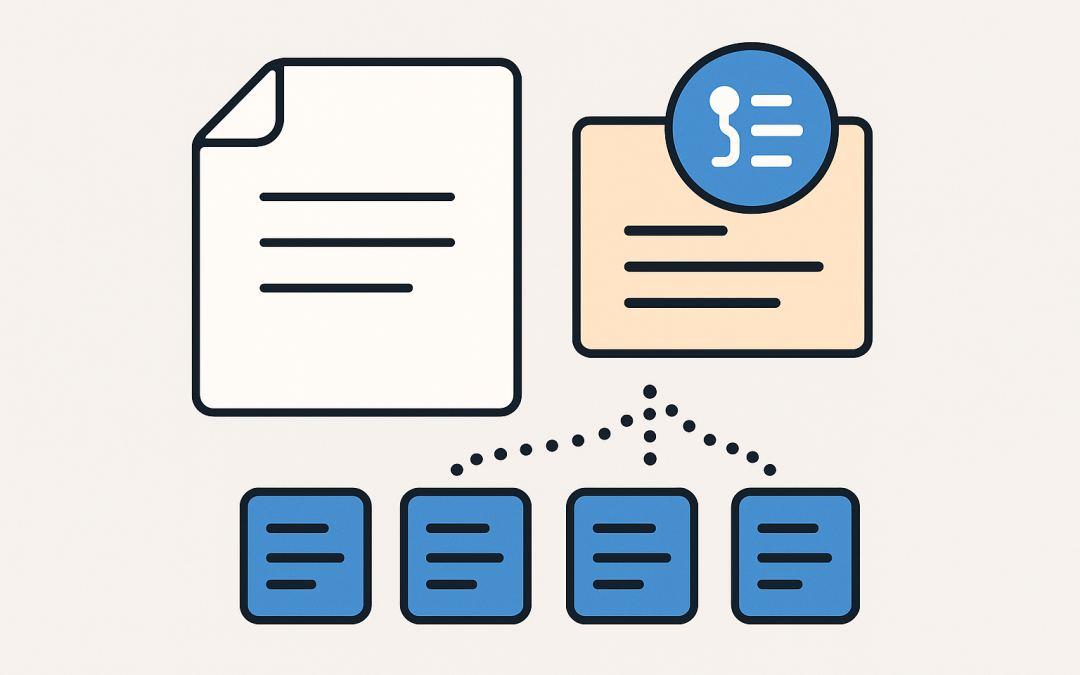
In this blog post Mastering Document Definition in LangChain for Reliable RAG we will explore what a Document means in LangChain, why it matters, and how to structure, chunk, and store it for robust retrieval-augmented generation (RAG). At a high level, LangChain uses...